CUDA 커널 함수를 개시하면 커널 함수를 수행할 스레드 그리드를 생성한다.
=> 커널 함수는 프로그램 실행 중 커널이 개시될 때 생성되는 스레드들이 수행할 C 문장들을 정의
▶CUDA 스레드의 구성
그리드 내부의 스레드들은 모두 동일한 커널 함수를 실행하기 때문에 식별하고 사용할 데이터 영역을 구별하기 위해 고유한 좌표값을 사용한다.
스레드들의 고유한 좌표값은 CUDA Luntime 이 부여한다.
- blockIdx(block index), threadIdx(thread index) : 커널 함수가 사용하도록 초기화된 변수로 주어진다.
- 스레드가 커널 함수 수행 중 blockIdx, threadIdx 변수를 참조하면 스레드의 좌표를 얻게 된다.
- gridDim, blockDim
그림 4.1 예제 :
- 그리드는 N개의 스레드 블록으로 구성되며 각각 0에서 N-1까지의 blockIdx.x값을 갖는다.
- 각 블록은 M개의 스레드로 구성되며 0~M-1까지의 threadIdx.x값을 갖는다.
- 그리드 계층의 모든 블록은 1차원 배열로 구성, 각 블록 내부의 스레드들도 1차원 배열로 구성된다.
- 하나의 그리드 : 총 N*M개의 스레드를 갖는다.

//커널 코드의 일부
int threadId = blockIdx.x *
blockDim.x + threadIdx.x;
...
float x = input (threadId);
float y = func(x);
output(threadId) = y;
...threadId = blockIdx.x * blockDim.x + threadIdx.x 식으로 계산된 값으로 입,출력 데이터를 읽고 쓸 위치를 알 수 있다.
블록0의 스레드3 은 0*M+3 = 3 threadID를 가짐 블록 5의 스레드 3은 5*M+3 threadID 값을 가짐.
그리드가 128개의 블록을 갖고(N=128) 한 블록이 32개의 스레드를 갖을 경우(M=32)
커널에서 blockDim을 읽으면 32 return.
한 그리드의 총 스레드 수는 128X32 = 4096개의 스레드가 있다.
일반적으로 그리드는 2차원 배열 블록으로, 한 블록은 3차원 배열의 스레드로 구성된다.
커널이 개시될 때 그리드가 구성되며 다음 변수와 같이 표시된다.
//실행 설정 변수들을 초기화
dim3 dimGrid(128,1,1); //(그리드 크기, 블록 크기)
dim3 dimBlock(32,1,1); //1차원
kernelFunction <<<dimGrid, dimBlock>>>(...);
//2차원 그리드
dim3 dimGrid(2,2,1);
dim3 dimBlock(4,2,2);
kernel Function <<<dimGrid, dimBlock>>>(...);
//2X2 배열로 구성된 4개의 블록으로 구성된다.각 threadIdx 는 3개의 원소로 구성됨
x 좌표 : threadIdx.x
y 좌표 : threadIdx.y
z 좌표 : threadIdx.z
블록의 각 차원에 있는 스레드의 개수는 커널을 개시할 때 실행 설정 변수의 두 번째 변수로 지정된다.
미리 정의된 struct 변수 blockDim 을 사용하여 접근 가능
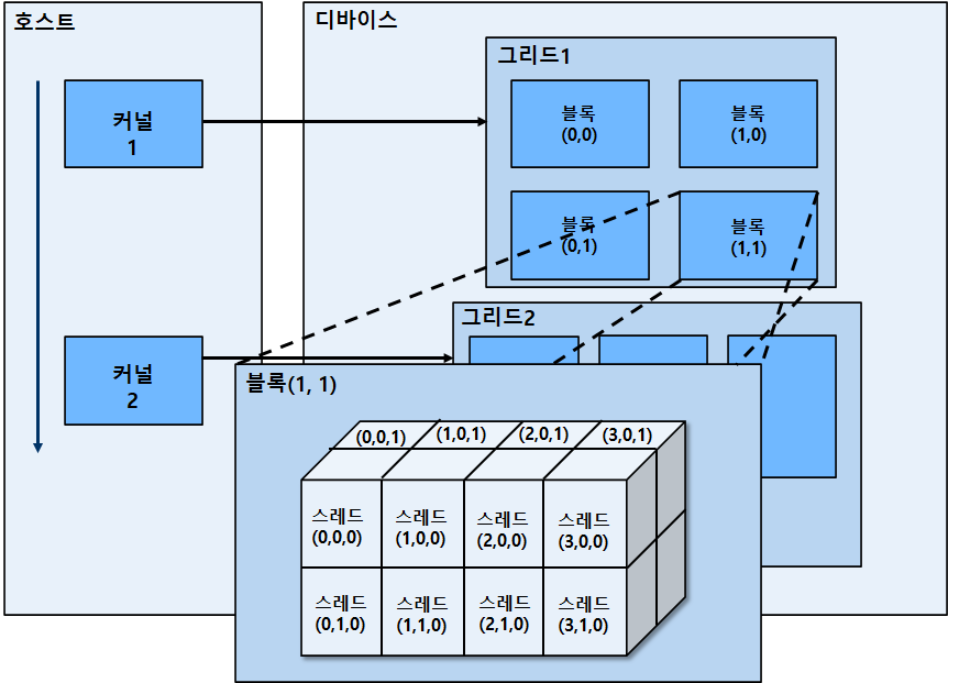
그림 4.2에서 각 블록은 4x2x2 배열의 스레드로 구성되며 그리드의 모든 블록은 크기가 동일하다.
블록(1,1)은 16개의 스레드를 포함하며 스레드(2,1,0) : threadIdx.x=2, threadIdx.y=1, threadIdx.z=0
▶ 동기화와 투명한 확장가능성
CUDA의 한 블록의 스레드들은 배리어 동기화(barrier synchronization)함수 __syncthreads()를 통해 작업을 조율할 수 있다.
커널이 __syncthreads() 호출시 호출을 수행한 스레드는 블록에 있는 모든 스레드가 그 지점에 도달할 때까지 호출한 자리에 멈춘다.
=> 블록 내의 스레드는 다음 작업을 진행 전에 현재 커널 실행을 모두 마칠 수 있다.
syncthreads() 는 블록의 모든 스레드에 의해 실행되며 if 문에 있다면 syncthread() 를 포함하던지, 아예 다른 경로를 사용해야 함.
동기화는 블록 내의 스레드 실행에 제약을 가함.
CUDA 런타임은 블록의 모든 스레드에 동일한 실행 자원을 할당해, 블록 내의 모든 스레드가 비슷한 시기에 실행이 되고 배리어 동기화로 인한 심각한 지연을 피할 수 있음.
투명한 확장 가능성(transparent scalability) : 다른 실행 자원을 갖는 하드웨어에서 동일한 코드 실행을 하도록 하는 것.
▶스레드의 할당
커널 lunched -> CUDA 런타임이 해당되는 스레드의 그리드 생성 -> 이 스레드들을 블록 단위로 실행 자원에 할당
SM(streaming multiprocessor) 이 여러 개의(최대) 블록을 할당받고, 여러 개의 블록을 동시에 실행하기에 자원이 충분하지 않은 경우 CUDA 런타임은 자동적으로 SM에 할당되는 블록의 숫자를 줄여 자원의 부족을 막는다.
런타임 시스템은 실행할 블록의 리스트를 관리하면서 이전에 할당된 블록이 끝나면 새로운 블록을 SM에 할당한다.

그림 4.9 는 각 SM에 3개의 스레드 블록이 할당됨.
SM자원의 제약 중 하나로, SM이 스레드, blockID, 실행 상태를 추적하기 위해 하드웨어 자원이 필요하다.
▶ 스레드 스케줄링과 지연시간 감내
하나의 블록은 하나의 SM에 할당되며, 워프(warp)인 32개의 스레드 유닛으로 나뉜다.
워프의 크기는 구현에 따라 정할 수 있으며 SM에서 워프는 스레드 스케줄링의 단위이다.
각 워프는 연속된 threadIdx 값을 갖는 32개의 스레드로 구성된다.
한 개의 SM에 3개의 블록(블록1, 블록2, 블록3)이 할당됐을 경우, 각 블록들은 스케줄링 목적으로 워프로 더 나눠진다.
▶전역 메모리 접근과 같은 지연시간이 오래 걸리는 연산을 CUDA 프로세서거 어떻게 효율적으로 실행시키는가?
워프가 실행할 때 우선수니 메카니즘을 따라 하나의 워프가 선택된다.
비싼 연산의 긴 지연시간을 다른 스레드의 작업으로 채우는 방법을 사용 : 지연시간 은닉(latency hiding)
무-부하 스레드 스케줄링(zero-overhead thread scheduling) : 실행이 가능한 워프를 선택하여 실행 시간을 지연시키지 않는 것
이러한 긴 지연시간을 감내하는 기능으로 인해 GPU는 보통 CPU가 cache memory와 분기 예측을 위해 사용하는 칩의 면적을 그만큼 필요로 하지 않는다.
'CUDA' 카테고리의 다른 글
| 5장 CUDA 메모리 (0) | 2021.07.12 |
|---|---|
| 3장 CUDA의 기초 (1) | 2021.06.30 |
| 1장 서론 (1) | 2021.06.29 |